Reasoning over long sequences of observations and actions is essential for many robotic tasks. Yet, learning effective long-context policies from demonstrations remains challenging. As context length increases, training becomes increasingly expensive due to rising memory demands, and policy performance often degrades as a result of spurious correlations. Recent methods typically sidestep these issues by truncating context length, discarding historical information that may be critical for subsequent decisions. In this paper, we propose an alternative approach that explicitly regularizes the retention of past information. We first revisit the copycat problem in imitation learning and identify an opposite challenge in recent diffusion policies: rather than over-relying on prior actions, they often fail to capture essential dependencies between past and future actions. To address this, we introduce Past-Token Prediction (PTP), an auxiliary task in which the policy learns to predict past action tokens alongside future ones. This regularization significantly improves temporal modeling in the policy head, with minimal reliance on visual representations. Building on this observation, we further introduce a multistage training strategy: pre-train the visual encoder with short contexts, and fine-tune the policy head using cached long-context embeddings. This strategy preserves the benefits of PTP while greatly reducing memory and computational overhead. Finally, we extend PTP into a self-verification mechanism at test time, enabling the policy to score and select candidates consistent with past actions during inference. Experiments across four real-world and six simulated tasks demonstrate that our proposed method improves the performance of long-context diffusion policies by 3× and accelerates policy training by more than 10×.
One major challenge in long-context imitation learning is causal confusion, where policies latch onto spurious correlations in the input context that do not truly influence expert behavior. This issue worsens with longer contexts, leading to overfitting during training and poor generalization at deployment. A classic example is copycat behavior, where the model simply mimics past actions without understanding their relationship to observations. However, our findings reveal a different trend: modern policies tend to under-utilize, rather than over-rely on, temporal action dependencies.
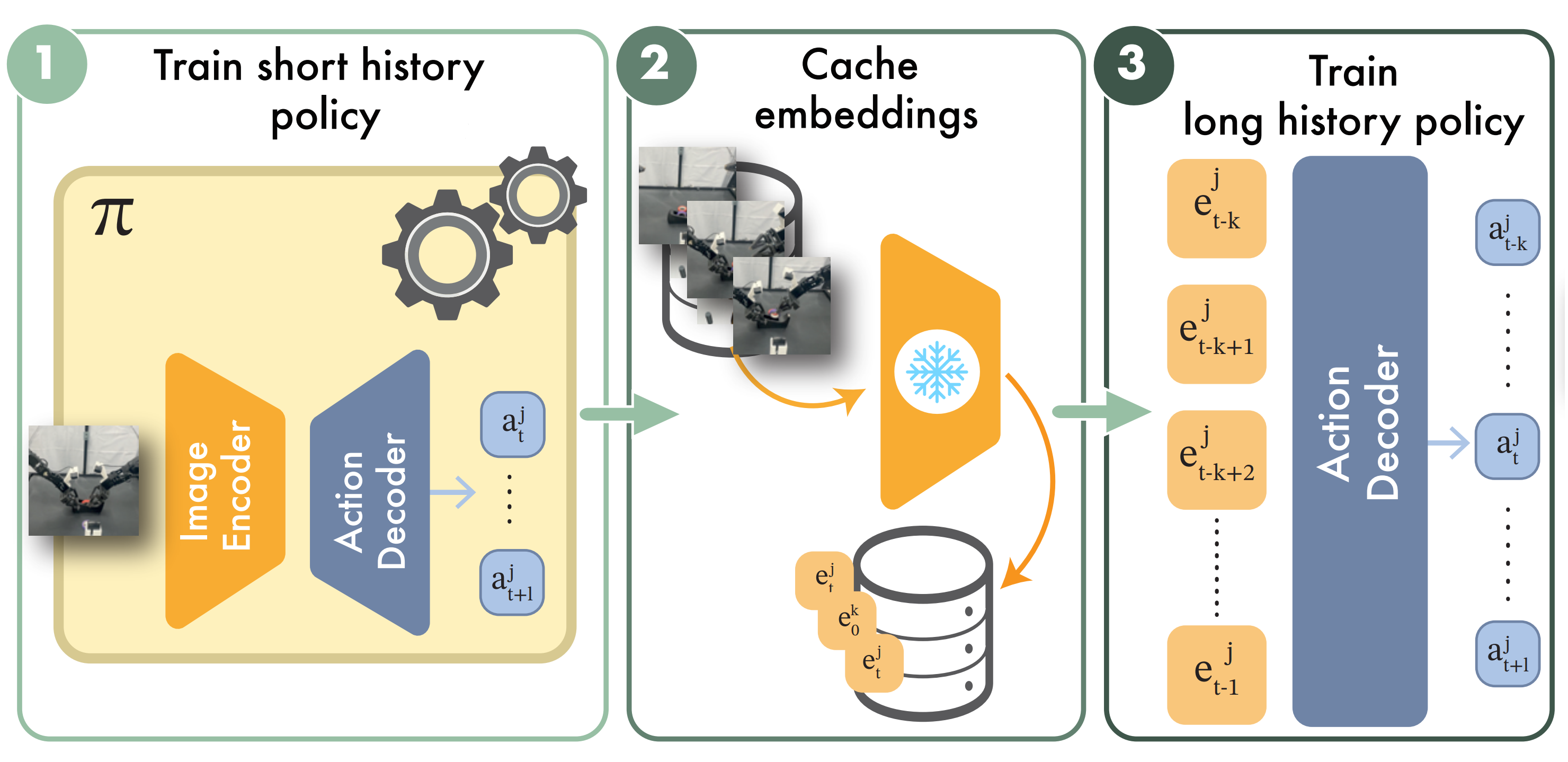
Building upon our analysis, we introduce a simple yet effective method for long-context imitation learning. At the core is Past-Token Prediction (PTP), an auxiliary objective that tasks the policy to predict both past and future actions. This task encourages the model to better capture action dependencies over time. To scale PTP efficiently, we propose a multi-stage training recipe that freezes a short-horizon encoder, caches visual features, and trains the policy head using these cached embeddings. At test time, we extend PTP into a self-verification mechanism: the policy samples multiple candidate sequences and selects the one that best reconstructs the already-executed actions.
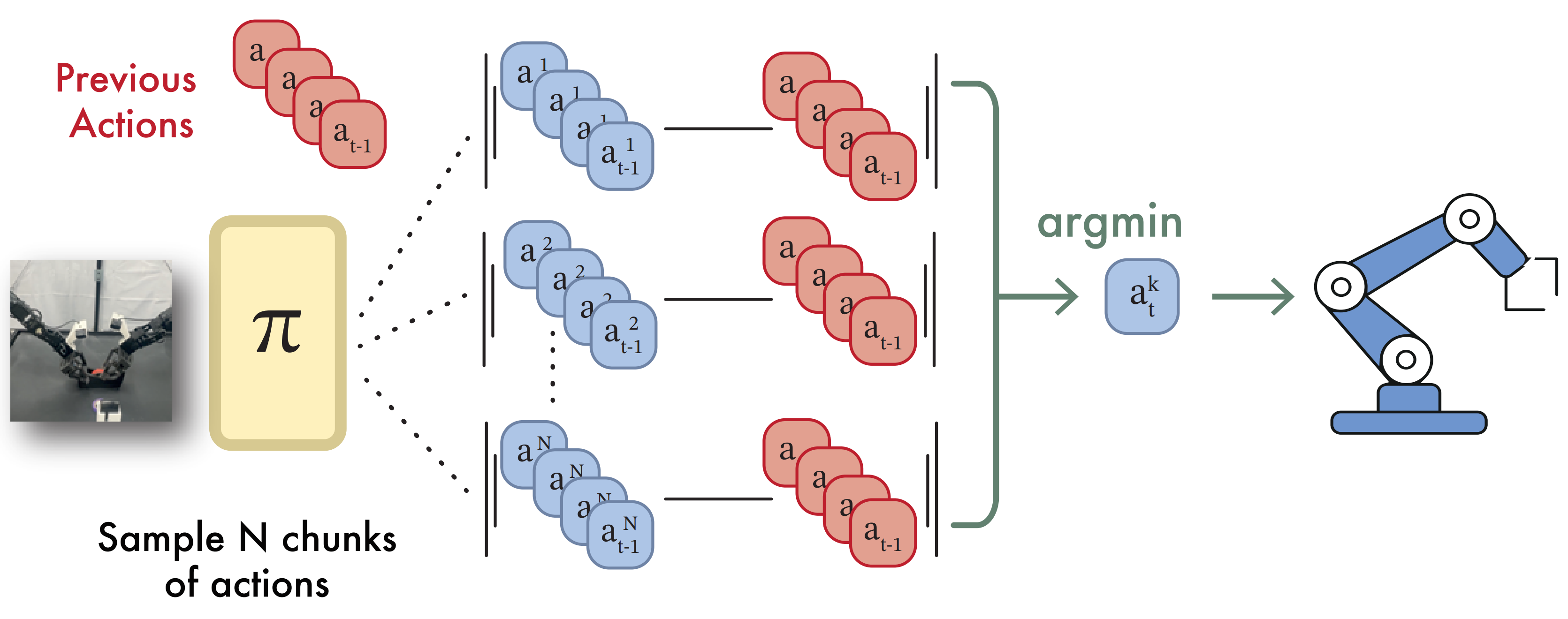
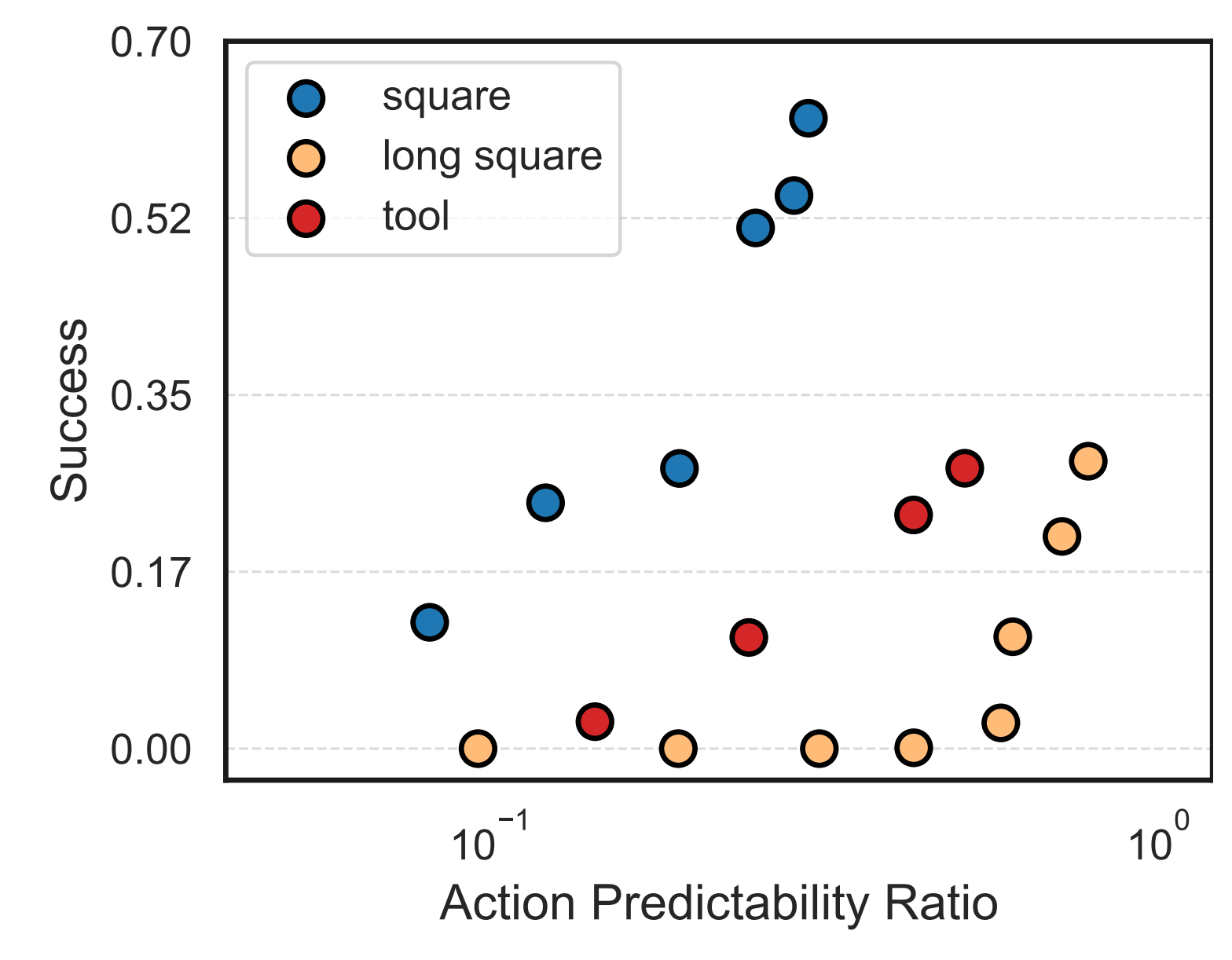
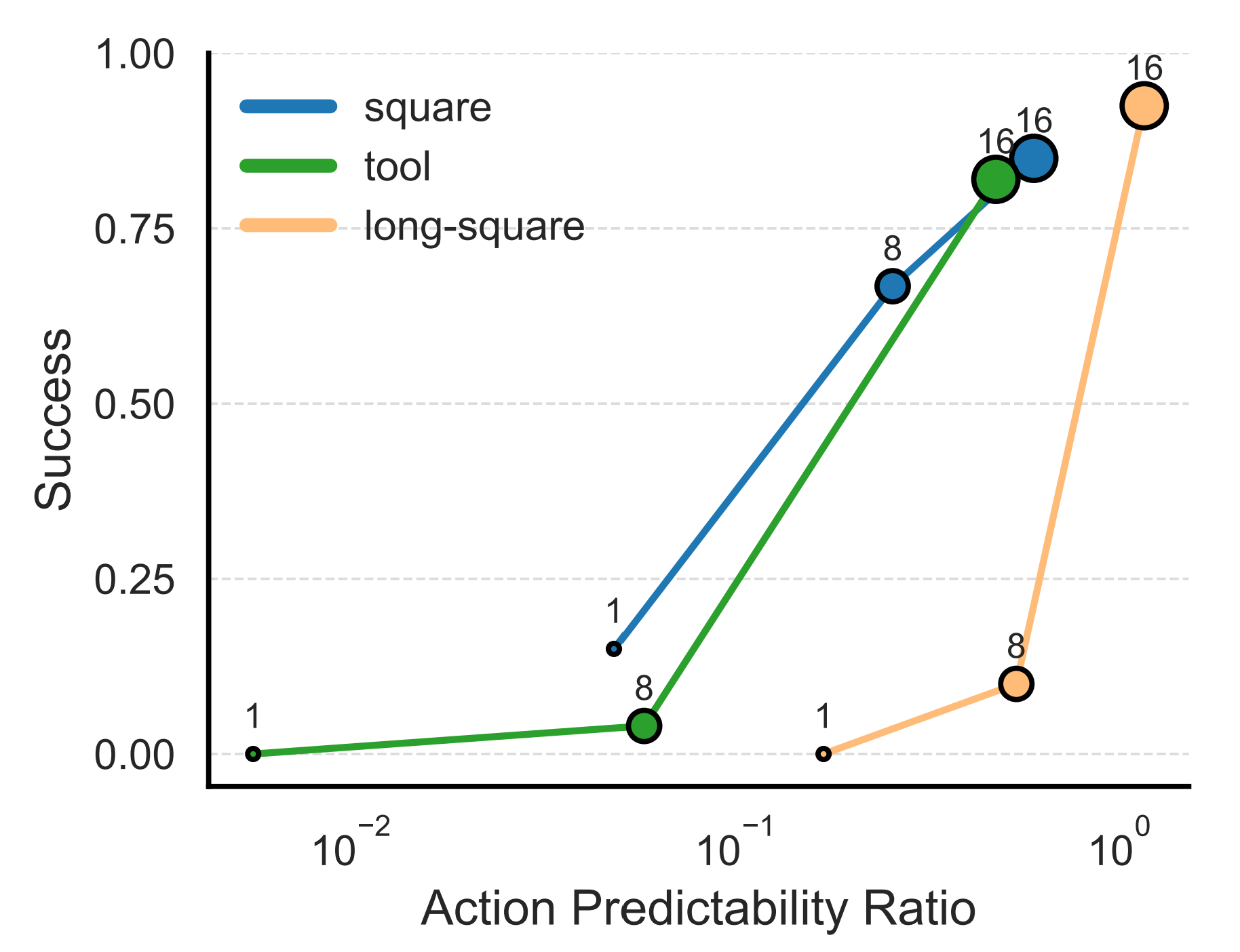
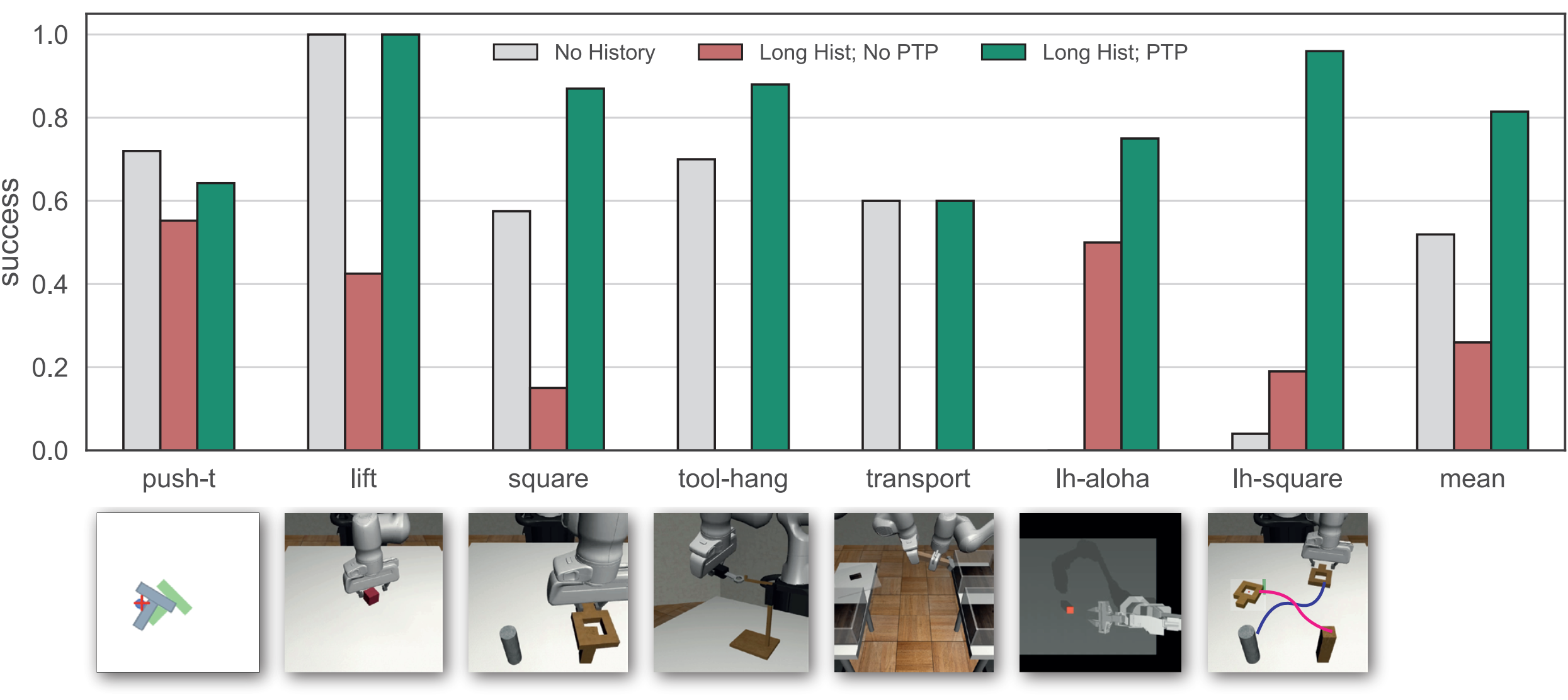
We evaluate our method on seven simulation tasks, including four from the RobotMimic benchmark and two newly designed long-horizon tasks that require historical context. Our approach significantly outperforms short-context and long-context baselines, especially in challenging manipulation scenarios.
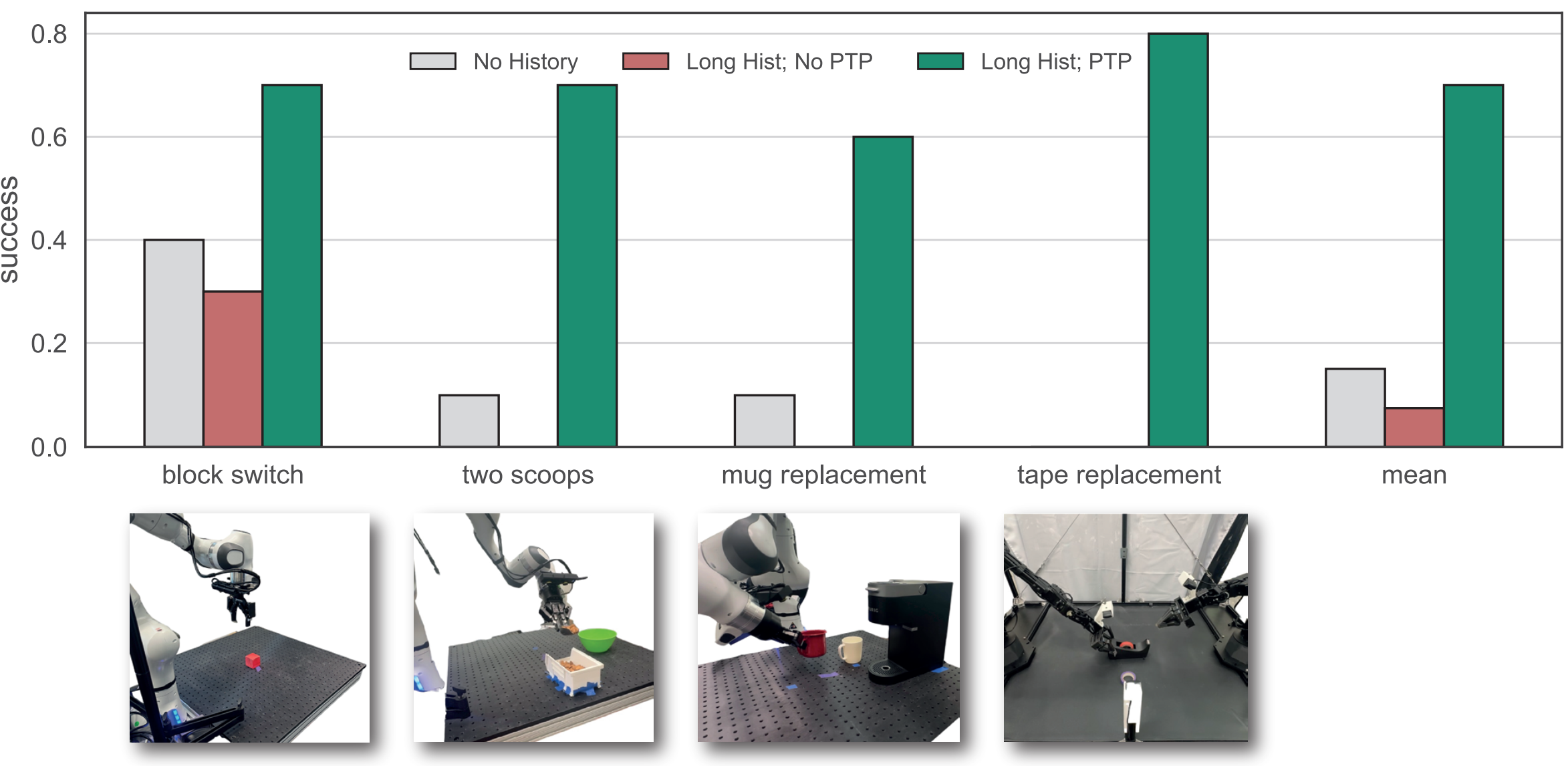
We evaluate our method on four real-world tasks, each requiring historical context for task completion:
Our method consistently outperforms both short-context and long-context baselines across all four tasks.